CUDA编程模型
一点小小的记录
CUDA编程模型
用 __global__(对host和device都可见) 声明指定符定义内核,并通过新的 <<<...>>> 指定内核调用中执行该内核的 CUDA 线程数量。每个执行内核的线程都会获得一个唯一的线程 ID,该 ID 可通过内置变量在内核中访问。执行流如下
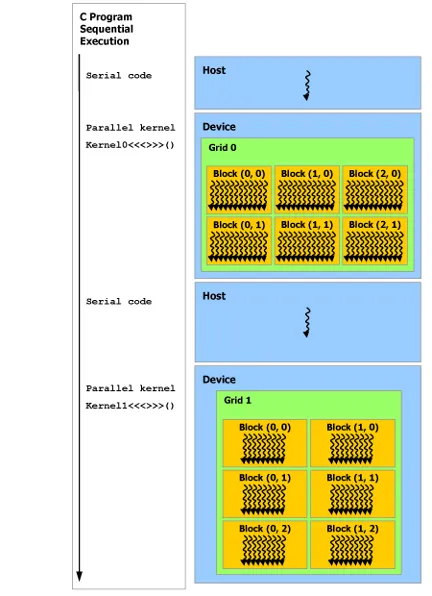
线程层次结构
threadIdx是一个三维向量,可以自然的表示向量矩阵体积,索引和线程ID的计算关系为 ID 是 (x + y Dx);对于大小为 (Dx, Dy, Dz) 的三维块,索引为 (x, y, z) 的线程的线程 ID 是 (x + y Dx + z Dx Dy)。也就是按x索引到Dx之后y索引进一
 一个grid 的具体规模是由启动参数确定的,并且支持dim3类型,也就是说你可以
一个grid 的具体规模是由启动参数确定的,并且支持dim3类型,也就是说你可以
_global__ void process3D_kernel(float* data, int Dx, int Dy, int Dz) {
// 计算全局三维索引 x, y, z
int ix = blockIdx.x * blockDim.x + threadIdx.x;
int iy = blockIdx.y * blockDim.y + threadIdx.y;
int iz = blockIdx.z * blockDim.z + threadIdx.z;
// 边界检查,防止多余的线程访问越界内存
if (ix < Dx && iy < Dy && iz < Dz) {
// 将三维坐标 (ix, iy, iz) 转换成一维线性内存地址
int linear_index = iz * (Dx * Dy) + iy * Dx + ix;
// 对 data[linear_index] 执行计算...
data[linear_index] = data[linear_index] * 2.0f; // 示例操作
}
}
// 假设我们的3D数据尺寸是 512 x 512 x 256
int Dx = 512, Dy = 512, Dz = 256;
// 1. 定义每个Block的维度。
// 我们让每个Block处理一个 8x8x4 的子体积
dim3 threadsPerBlock(8, 8, 4); // 总共 8*8*4 = 256 个线程,是个不错的选择
// 2. 计算需要多少个Block来覆盖整个三维数据
dim3 numBlocks( (Dx + threadsPerBlock.x - 1) / threadsPerBlock.x, // 512/8 = 64
(Dy + threadsPerBlock.y - 1) / threadsPerBlock.y, // 512/8 = 64
(Dz + threadsPerBlock.z - 1) / threadsPerBlock.z ); // 256/4 = 64
// 3. 启动内核
process3D_kernel<<<numBlocks, threadsPerBlock>>>(data, Dx, Dy, Dz);也就是说提供了一种直观的表示多维数据的方法,并且暴露了等价一维数据的并行性。
一个block内的threads可以通过共享部分的镍村和进行同步/异步操作来协调内存访问,通过调用 __syncthreads() 内建函数在内核中指定同步点
计算能力9.0引入了cluster,集群中的所有线程块都保证在单个 GPU 处理集群(GPC)上协同调度,并允许集群中的线程块使用集群组 API cluster.sync() 执行硬件支持的同步。
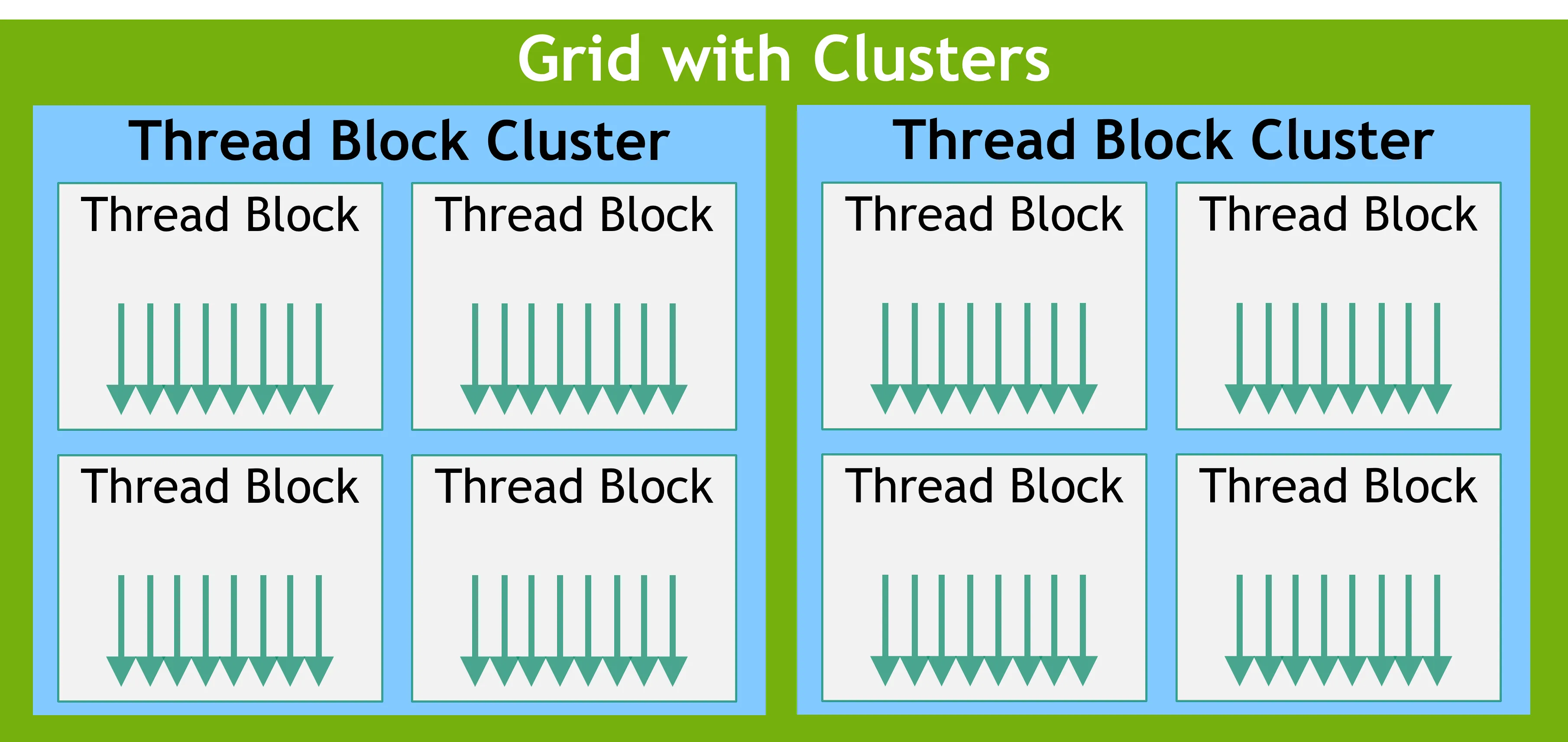
内存层次结构
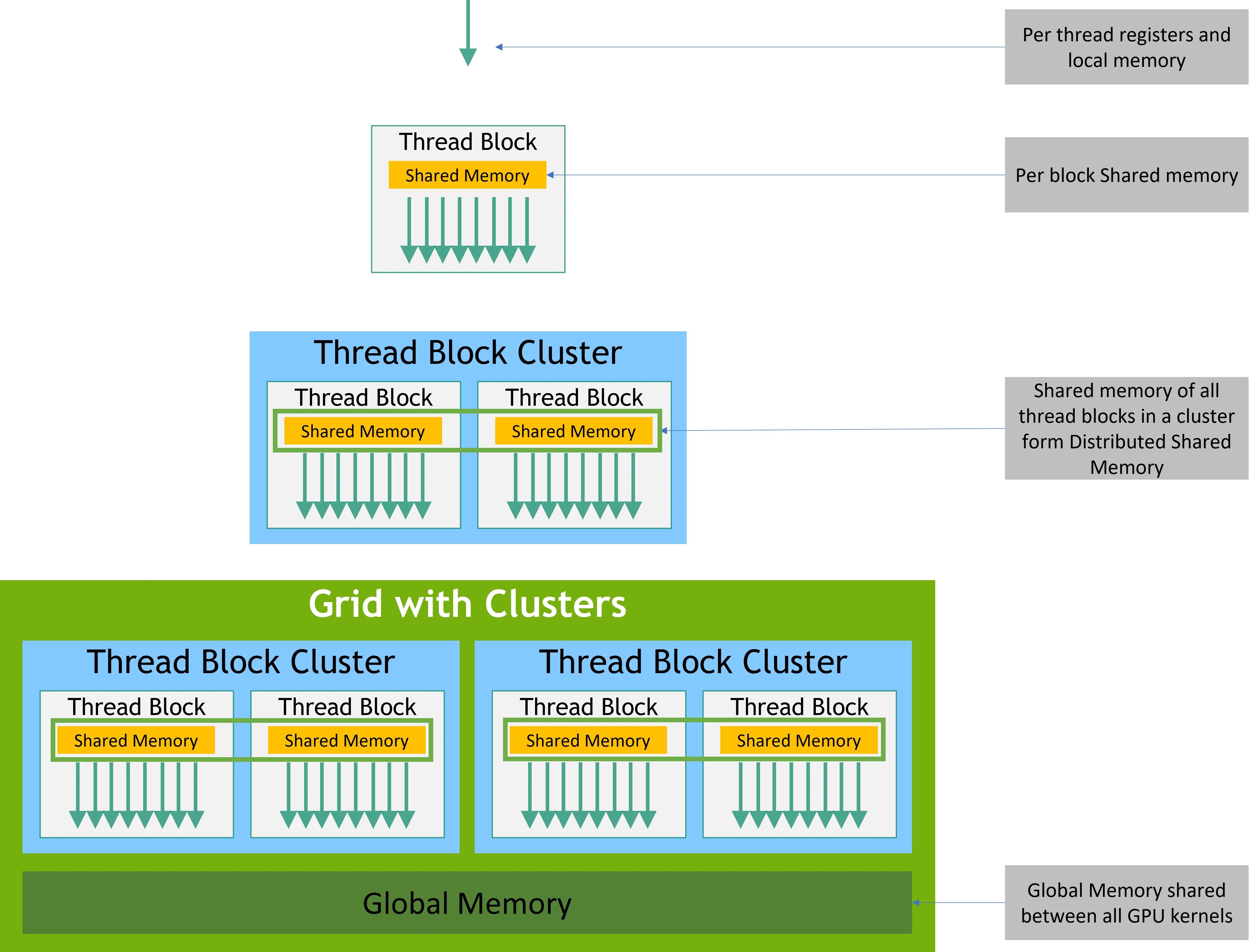 如图所示,每个thread拥有他本身的寄存器和内存,同时拥有该block共享的 shared Memory 通过cluster设置还能访问同一个cluster中不同block共享内存。
如下图所示,CUDA 的内存层次结构可以从线程、线程块(Thread Block)、线程块集群(Thread Block Cluster)到整个网格(Grid)进行划分:
如图所示,每个thread拥有他本身的寄存器和内存,同时拥有该block共享的 shared Memory 通过cluster设置还能访问同一个cluster中不同block共享内存。
如下图所示,CUDA 的内存层次结构可以从线程、线程块(Thread Block)、线程块集群(Thread Block Cluster)到整个网格(Grid)进行划分:
1. 每线程(Per-Thread)私有内存
-
寄存器 (Registers) 和 本地内存 (Local Memory) 是每个线程私有的存储空间。
-
作用域: 仅限当前线程访问,其他任何线程都无法直接读写。
2. 每线程块(Per-Block)共享内存
-
共享内存 (Shared Memory) 是每个线程块(Thread Block)内所有线程共享的内存区域。
-
作用域: 同一个线程块内的所有线程均可访问。不同线程块之间的共享内存是相互隔离的。
3. 每集群(Per-Cluster)分布式共享内存
-
分布式共享内存 (Distributed Shared Memory) 是一个较新的概念,它建立在 线程块集群(Thread Block Cluster) 之上。一个集群由多个线程块组成。
-
作用域: 同一个集群内的所有线程块中的所有线程,都可以相互访问彼此的共享内存。
4. 全局内存(Global Memory)
-
全局内存 (Global Memory) 是最大、最主要的 GPU 显存。
-
作用域: 网格(Grid)内的所有线程,以及主机(CPU)都可以访问。
-
特点: 全局内存是整个 GPU 架构中容量最大但访问速度最慢的内存。所有核函数(Kernel)的输入数据和最终的计算结果通常都存放在这里。虽然其延迟较高,但现代 GPU 通过大量的并行线程来隐藏这部分延迟,并且拥有高带宽的特性。
| 内存类型 | 作用域 | 位置 | 访问速度 | 主要用途 |
| 寄存器 | 单个线程 | 片上 (On-chip) | 最快 | 线程私有变量 |
| 本地内存 | 单个线程 | 片外 (Off-chip) DRAM | 较慢 | 寄存器溢出、线程私有数组 |
| 共享内存 | 线程块内所有线程 | 片上 (On-chip) SRAM | 很快 | 块内线程间数据共享与协作 |
| 分布式共享内存 | 集群内所有线程 | 片上 (On-chip) SRAM | 很快 | 集群内跨线程块的数据共享与协作 |
| 全局内存 | 网格内所有线程+主机 | 片外 (Off-chip) DRAM | 最慢 | GPU 与主机间的数据交换、大规模数据存储 |
SIMT架构
在理解了 CUDA 如何组织线程和内存之后,下一个关键问题是:GPU 硬件究竟是如何执行成千上万个线程的?答案就是 SIMT(Single Instruction, Multiple Thread,单指令,多线程) 架构。
从根本上说,SIMT 是一种执行模型,它允许 GPU 以极高的效率并行处理大量线程。
GPU 的多处理器并不会逐个独立地管理线程,而是将它们以 32 个并行线程为一组进行创建、管理、调度和执行。这样一组线程被称为一个 Warp。
-
创建与调度:当一个线程块(Block)被分配给一个多处理器执行时,它会被划分为多个 Warp。划分方式是固定的:第一个 Warp 包含 thread 0 到 31,第二个 Warp 包含 thread 32 到 63,以此类推。硬件中的 Warp 调度器 负责调度这些 Warp 的执行。
-
独立执行:虽然同一个 Warp 中的所有线程从相同的程序地址开始,但每个线程都拥有自己独立的指令地址计数器和寄存器状态。这意味着它们可以根据各自的数据进行分支和独立执行。
Warp 的执行与分支
一个 Warp 在任意时刻只执行一条共同的指令。因此,当 Warp 中的所有 32 个线程都遵循相同的执行路径时,可以实现 100% 的硬件利用率。
然而,如果线程遇到了依赖于数据的条件分支(例如 if-else 语句),并且 Warp 内的线程做出了不同的选择,就会发生分支分化(Branch Divergence)。 当发生分化时,Warp 会串行地执行每个分支路径。在执行其中一个分支时,选择了另一条路径的线程会被暂时禁用(变为非活动状态)。当一个分支执行完毕后,再执行另一个分支,直到所有路径都走完,线程重新汇合。显然这是一种效率很低的模型,参考过一些CPU ALU设计的同学应该就想到了,通过牺牲一些面积,让每个thread都完整无阻塞的执行完毕,最后再选出需要的结果就行了
```c++
__global__ void data_dependent_divergent_kernel(float* data, const float threshold, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
float value = data[idx];
// 真正的数据依赖分支!
if (value < threshold) { // [!code error]
// 路径 A: 只有满足条件的线程会执行
data[idx] = value * 2.0f;
} else {
// 路径 B: 其他线程会执行
data[idx] = value * 0.5f;
}
}
}
``````c++
__global__ void branchless_ternary_kernel(float* data, const float threshold, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
float value = data[idx];
// 1. 无条件并行计算两个路径的结果
float result_if_true = value * 2.0f;
float result_if_false = value * 0.5f;
// 2. 获取数据依赖的条件
bool condition = (value < threshold);
// 3. 根据条件选择结果,这通常会被编译成一条无分支的指令
data[idx] = condition ? result_if_true : result_if_false;
}
}
```SIMT vs. SIMD
SIMT 架构与传统的 SIMD(Single Instruction, Multiple Data,单指令,多数据) 向量组织很相似,都是用一条指令控制多个处理单元。但它们之间有一个关键区别:
-
SIMD 将向量宽度(SIMD width)暴露给软件,程序员需要手动将数据合并成向量,并管理分支。这增加了编程的复杂性。
-
SIMT 则为程序员提供了一个更友好的抽象。程序员只需编写单个线程的执行和分支行为,硬件会自动将这些标量线程分组到 Warp 中执行。
当然cuda也提供了一些SIMD指令 为了保证程序的正确性,程序员几乎可以忽略 SIMT 的行为。但是,为了追求极致性能,就必须精心设计代码,尽量避免 Warp 内的线程发生分化。这与传统 CPU 编程中考虑缓存行(Cache Line)大小来优化性能是类似的道理。
架构的演进:从 Warp 同步到独立线程调度
SIMT 架构本身也在不断发展,其中最重要的一项变革发生在 NVIDIA Volta 架构上。
-
Volta 之前(Warp-Synchronous):
在早期的架构中,一个 Warp 内的所有 32 个线程共享一个程序计数器,并使用一个活动掩码来标记哪些线程是活动的。这种模式被称为**“Warp 同步”(Warp-Synchronous)**,意味着在同一条指令上,Warp 内的线程要么都在执行,要么都已停止。这种隐式的同步特性有时会被程序员利用来进行一些无锁的优化(例如,Warp 内的归约操作)。但它也限制了灵活性,在需要细粒度数据共享时,很容易导致死锁。 -
Volta 及之后(Independent Thread Scheduling):
从 Volta 架构开始,NVIDIA 引入了独立线程调度(Independent Thread Scheduling)。在这种新模型下,GPU 会为每个线程维护独立的执行状态,包括程序计数器和调用堆栈。-
灵活性:这带来了前所未有的灵活性。线程可以在**子 Warp 级别(sub-warp granularity)**上分化和重新收敛。调度优化器会智能地将来自同一 Warp 的活动线程重新组合成 SIMT 单元来执行,既保留了 SIMT 的高吞吐量,又打破了过去 32 个线程必须步调一致的刚性约束。
-
注意事项:这一变化也意味着,那些依赖于旧的“Warp 同步”假设的代码可能在 Volta 及更新的 GPU 上无法正常工作。任何依赖隐式同步的代码都需要重新审查,以确保其兼容性。
-
硬件多线程与延迟隐藏
GPU 能够在硬件层面支持大量的并发 Warp。每个 Warp 的执行上下文(程序计数器、寄存器等)在其整个生命周期内都保存在片上(on-chip)硬件中。
这使得切换不同 Warp 的执行上下文是零成本的。在每个指令周期,Warp 调度器都会选择一个已准备好执行下一条指令的 Warp,并将指令分派给它。如果一个 Warp 因为等待内存操作(例如从全局内存读取数据)而停顿,调度器可以立即切换到另一个就绪的 Warp 继续执行计算。
这种硬件多线程机制是 GPU 实现**延迟隐藏(Latency Hiding)**的关键。通过保持大量的活动 Warp,GPU 可以用有用的计算来“填补”内存访问等长延迟操作所造成的等待时间,从而最大化计算资源的利用率。
20.10. Compute Capability 12.0
20.10. 计算能力 12.0
20.10.1. Architecture 20.10.1. 架构
A Streaming Multiprocessor (SM) consists of:
流式多处理器(SM)由以下部分组成:
-
128 FP32 cores for single-precision arithmetic operations,
128 个用于单精度运算的 FP32 核心, -
2 FP64 cores for double-precision arithmetic operations,
2 个用于双精度运算的 FP64 核心, -
64 INT32 cores for integer math,
64 个 INT32 核用于整数运算, -
Mixed-precision fifth-generation Tensor Core(s) supporting
FP8input type in eitherE4M3orE5M2for exponent (E) and mantissa (M), half-precision (fp16),__nv_bfloat16,tf32, INT8 and double precision (fp64) matrix arithmetic (see Warp Matrix Functions for details) with sparsity support,
支持FP8输入类型的混合精度第五代张量核,指数(E)和尾数(M)可在E4M3或E5M2中选择,支持半精度(fp16)、__nv_bfloat16、tf32、INT8 和双精度(fp64)矩阵运算(详细内容请参阅 Warp 矩阵函数),并支持稀疏性, -
16 special function units for single-precision floating-point transcendental functions,
16 个特殊功能单元用于单精度浮点超越函数, -
4 warp schedulers. 4 个线程束调度器。
An SM statically distributes its warps among its schedulers. Then, at every instruction issue time, each scheduler issues one instruction for one of its assigned warps that is ready to execute, if any.
SM 将其 warp 动态分配给其调度器。然后,在每个指令发出时间,每个调度器为其已分配且准备执行的 warp 发出一个指令,如果有的话。
An SM has: 一个流多处理器(SM)具有:
-
a read-only constant cache that is shared by all functional units and speeds up reads from the constant memory space, which resides in device memory,
一个对所有功能单元共享的只读常量缓存,它加速了对位于设备内存中的常量内存空间的读取, -
a unified data cache and shared memory with a total size of 100 KB for devices of compute capability 12.0
计算能力为 12.0 的设备配备了一个统一的 100 KB 数据缓存和共享内存
Shared memory is partitioned out of the unified data cache, and can be configured to various sizes (see Shared Memory). The remaining data cache serves as an L1 cache and is also used by the texture unit that implements the various addressing and data filtering modes mentioned in Texture and Surface Memory.
共享内存从统一数据缓存中划分出来,可以配置为不同的大小(参见共享内存)。剩余的数据缓存作为 L1 缓存使用,同时也被纹理单元使用,该单元实现了纹理和表面内存中提到的各种寻址和数据过滤模式。
CUDA 并行原语:从 Warp 到 Grid 的协作层次
背景介绍 在理解了 SIMT(单指令,多线程) 和 Warp(线程束) 是 GPU 执行与调度的基本单位之后,下一步自然就是理解线程之间如何交换数据、同步执行以及组织协作。
CUDA 提供了一套分层的并行原语。不同层级的原语,对应不同的通信范围、同步成本和性能特征。通常的分析顺序是从 Warp 开始,再到 Block,最后到 Grid。
第一层:Warp 级原语
这是开销最低的协作层级,协作范围严格限定在一个 Warp(通常是 32 个线程)内部。
层次特征:极致速度与隐式同步
- 通信介质:寄存器 (Register)。数据交换直接在线程的私有寄存器之间进行,完全绕过了共享内存或全局内存,延迟极低。
- 同步方式:隐式同步。由于一个 Warp 内的所有线程在硬件层面是“步调一致”的(执行同一条指令),因此这些原语本身就包含了同步的含义,无需额外的
__syncthreads()。
核心原语与实例
1. 数据交换 (Shuffle)
Shuffle 指令允许一个线程直接读取同一个 Warp 内另一个线程的寄存器值,是实现高效 Warp 内并行算法的基石。
#pragma unroll // 建议编译器展开这个循环
for (int offset = 16; offset > 0; offset >>= 1) {
// 从 laneId + offset 的线程获取值,并与自己的值比较
// 经过5次迭代,0号线程将持有整个Warp的最大值
val = fmaxf(val, __shfl_down_sync(0xFFFFFFFF, val, offset)); // [!code ++]
}// Warp内的0号线程持有一个关键数据
float key_data = 0.0f;
if (threadIdx.x % 32 == 0) {
key_data = 123.45f;
}
// 使用 __shfl_sync 将0号线程的 key_data 广播给Warp内所有其他线程
key_data = __shfl_sync(0xFFFFFFFF, key_data, 0); // [!code ++]
// 此后,Warp内所有线程的 key_data 都变成了 123.45f2. 投票与选举 (Vote)
Vote 指令用于快速检查 Warp 内有多少线程满足某个条件,并把结果广播给 Warp 内所有线程。
// 假设每个线程都在检查数据有效性
bool is_valid = check_data(input[idx]);
// __all_sync: 检查是否所有线程的数据都有效
// 只有当Warp内所有线程的 is_valid 都为 true 时,才会进入if块
if (__all_sync(0xFFFFFFFF, is_valid)) { // [!code ++]
// ... 执行只有数据全部有效时才能进行的操作 ...
}3. 信息聚合 (Ballot)
__ballot_sync 是投票的升级版,它返回一个32位的掩码,精确地告诉你哪些线程满足了条件。
// 假设我们要寻找输入数据中的所有负数
int predicate = (input[idx] < 0);
// ballot_result 的第 i 位为1,当且仅当第 i 号线程的 predicate 为 true
unsigned int ballot_result = __ballot_sync(0xFFFFFFFF, predicate); // [!code ++]
// 只让Warp的领头线程来分析和报告结果
if (threadIdx.x % 32 == 0) {
// __popc 是一个内置函数,用于计算一个整数中有多少个比特位是1
int negative_count = __popc(ballot_result);
if (negative_count > 0) {
printf("Warp %d 发现了 %d 个负数\n", threadIdx.x / 32, negative_count); // [!code warning]
}
}第二层:块级原语 (部门内部的协同会议)
当协作范围需要超出32个线程,但在一个线程块(Block)内部时,我们就进入了块级协作。
层次特征:共享内存与显式同步
- 通信介质:共享内存 (shared memory)。这是每个 SM 上的高速缓存,充当了块内所有线程(包括不同Warp)的公共白板。
- 同步方式:显式同步 (Barrier)。由于不同 Warp 的执行进度可能不一致,必须使用明确的指令
__syncthreads()来强制所有线程等待。
核心原语与实例
下面是使用共享内存实现块内归约的经典范例。
// 声明一块共享内存,大小与线程块相同
// 用于块内所有线程的数据交换
__shared__ float s_data[BLOCK_DIM]; // [!code ++]
// 每个线程从全局内存加载一个数据到共享内存
s_data[threadIdx.x] = input[idx];
// 进行块内同步,确保所有数据都已加载到共享内存
__syncthreads(); // [!code error]
// 在共享内存上进行并行归约
for (int s = BLOCK_DIM / 2; s > 0; s >>= 1) {
if (threadIdx.x < s) {
s_data[threadIdx.x] = fmaxf(s_data[threadIdx.x], s_data[threadIdx.x + s]);
}
__syncthreads(); // [!code error] // 每次归约后都需要同步
}第三层:Grid / 设备级原语
这是更高一级的协作方式,用于需要跨越多个独立线程块的场景。
层次特征:全局协作与高昂开销
- 通信介质:全局内存 (Global Memory)。这是不同块之间能够通信的唯一介质,速度最慢。
- 同步方式:非常有限。通常通过原子操作的互斥性来保证,或者通过
cudaDeviceSynchronize()在CPU侧进行全局同步。
核心原语与实例
atomicMax 是保证多个线程块同时更新全局变量时不出错的关键。
// 前面的代码已经计算出了每个线程块的最大值 block_max
// 只有块内的0号线程负责将结果汇报给总部
if (threadIdx.x == 0) {
// atomicMax 会原子地执行“读取-比较-写入”操作
// 确保来自成百上千个线程块的更新是线程安全的
atomicMax(global_output, block_max); // [!code ++]
}总结
在编写高性能 CUDA 程序时,我们的目标始终是:
尽可能在最低的层次(Warp > Block > Grid)用最快的原语解决问题。
从 Warp 内部的寄存器级数据交换,到 Block 内基于共享内存的协作,再到 Grid 层面的原子操作与全局同步,这些原语共同构成了 CUDA 并行程序设计最核心的协作机制。